Stories



-
![نبض الملاعب]()
نبض الملاعب
RT STORIES
الروسي بيفول يهزم آيفرت ويحتفظ بأحزمة "WBA" و"IBF" في الوزن الثقيل الخفيف
![الروسي بيفول يهزم آيفرت ويحتفظ بأحزمة "WBA" و"IBF" في الوزن الثقيل الخفيف]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
سافونوف يدخل تاريخ كرة القدم الروسية بعد تتويجه بدوري أبطال أوروبا للمرة الثانية
![سافونوف يدخل تاريخ كرة القدم الروسية بعد تتويجه بدوري أبطال أوروبا للمرة الثانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مفاجأة أنفيلد!.. صلاح وليفربول بعد رحيل سلوت
![مفاجأة أنفيلد!.. صلاح وليفربول بعد رحيل سلوت]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
باريس سان جيرمان يهزم أرسنال ويحتفظ بلقب دوري أبطال أوروبا
![باريس سان جيرمان يهزم أرسنال ويحتفظ بلقب دوري أبطال أوروبا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
باريس سان جيرمان يعادل رقم برشلونة القياسي في دوري الأبطال
![باريس سان جيرمان يعادل رقم برشلونة القياسي في دوري الأبطال]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
هافيرتز ينهي انتظار 20 عاما ويسجل أول هدف لأرسنال في نهائي دوري أبطال أوروبا
![هافيرتز ينهي انتظار 20 عاما ويسجل أول هدف لأرسنال في نهائي دوري أبطال أوروبا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الروسية شنايدر تهزم الأوكرانية أولينيكوفا وتتأهل للدور الرابع في "رولان غاروس"
![الروسية شنايدر تهزم الأوكرانية أولينيكوفا وتتأهل للدور الرابع في "رولان غاروس"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رد فعل محمد صلاح بعد إقالة أرني سلوت
![رد فعل محمد صلاح بعد إقالة أرني سلوت]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
أول تعليق من أرني سلوت بعد إقالته من تدريب ليفربول
![أول تعليق من أرني سلوت بعد إقالته من تدريب ليفربول]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رسميا.. ليفربول يعلن إقالة أرني سلوت
![رسميا.. ليفربول يعلن إقالة أرني سلوت]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
حسام حسن يعلن قائمة مصر النهائية لمونديال 2026
![حسام حسن يعلن قائمة مصر النهائية لمونديال 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بعد أنباء ضم محمد صلاح.. الاتحاد السعودي يرد على أنباء التعاقد مع يورغن كلوب
![بعد أنباء ضم محمد صلاح.. الاتحاد السعودي يرد على أنباء التعاقد مع يورغن كلوب]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رغم المنافسة التقليدية بين رونالدو وميسي.. جورجينا تفاجئ زوجة ميسي (صورة)
![رغم المنافسة التقليدية بين رونالدو وميسي.. جورجينا تفاجئ زوجة ميسي (صورة)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
شركة عالمية تتعاقد مع حمزة عبد الكريم بعد تألقه مع برشلونة
![شركة عالمية تتعاقد مع حمزة عبد الكريم بعد تألقه مع برشلونة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
النصر السعودي يتجه نحو المدرسة البرتغالية مجددا.. موعد إعلان اسم المدرب الجديد
![النصر السعودي يتجه نحو المدرسة البرتغالية مجددا.. موعد إعلان اسم المدرب الجديد]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رغم رحيله عن ليفربول.. محمد صلاح مرشح لجائزة جديدة (فيديو)
![رغم رحيله عن ليفربول.. محمد صلاح مرشح لجائزة جديدة (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
روبرتو مارتينيز يفجر مفاجأة بشأن رونالدو قبل انطلاق كأس العالم
![روبرتو مارتينيز يفجر مفاجأة بشأن رونالدو قبل انطلاق كأس العالم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مهاجم إيطالي يغير جنسيته إلى الأسترالية للمشاركة في كأس العالم 2026
![مهاجم إيطالي يغير جنسيته إلى الأسترالية للمشاركة في كأس العالم 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![نبض الملاعب]() نبض الملاعب
نبض الملاعب
-
![إسرائيل تواصل غاراتها على لبنان]()
إسرائيل تواصل غاراتها على لبنان
RT STORIES
بن غفير يدعو لسحق ضاحية بيروت الحنوبية ويطالب نتنياهو بتجاوز خط أحمر وضعه ترامب لإسرائيل في لبنان
![بن غفير يدعو لسحق ضاحية بيروت الحنوبية ويطالب نتنياهو بتجاوز خط أحمر وضعه ترامب لإسرائيل في لبنان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
القناة 13: الجيش الإسرائيلي يوصي بالبقاء في المناطق التي سيطر عليها بلبنان في أي اتفاق مستقبلي
![القناة 13: الجيش الإسرائيلي يوصي بالبقاء في المناطق التي سيطر عليها بلبنان في أي اتفاق مستقبلي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
سلام يحذر إسرائيل من مواصلة سياسة "الأرض المحروقة" في لبنان
![سلام يحذر إسرائيل من مواصلة سياسة "الأرض المحروقة" في لبنان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لبنان.. حزب الله يعلن عن إيقاع قوة إسرائيلية في كمين أثناء تقدمها باتجاه أطراف بلدة دبين
![لبنان.. حزب الله يعلن عن إيقاع قوة إسرائيلية في كمين أثناء تقدمها باتجاه أطراف بلدة دبين]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"قناة 12" العبرية: حزب الله أطلق 5 صواريخ تجاه مدينة صفد بالجليل الأعلى شمالي إسرائيل (فيديو)
!["قناة 12" العبرية: حزب الله أطلق 5 صواريخ تجاه مدينة صفد بالجليل الأعلى شمالي إسرائيل (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إعلام: الجيش الإسرائيلي يتوغل شمال الليطاني ويصل إلى تخوم النبطية والجيش اللبناني يخلي مواقعه
![إعلام: الجيش الإسرائيلي يتوغل شمال الليطاني ويصل إلى تخوم النبطية والجيش اللبناني يخلي مواقعه]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش اللبناني: إصابة عسكريين بجروح بليغة إثر غارة إسرائيلية استهدفت سيارتهما
![الجيش اللبناني: إصابة عسكريين بجروح بليغة إثر غارة إسرائيلية استهدفت سيارتهما]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
جنوب لبنان.. حزب الله يستهدف دبابة إسرائيلية في بلدة زوطر الشرقية
![جنوب لبنان.. حزب الله يستهدف دبابة إسرائيلية في بلدة زوطر الشرقية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الدفاع الأمريكية: المحادثات الأمنية بين إسرائيل ولبنان كانت "بناءة"
![الدفاع الأمريكية: المحادثات الأمنية بين إسرائيل ولبنان كانت "بناءة"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لبنان.. ارتفاع حصيلة ضحايا العدوان الإسرائيلي إلى 3355 قتيلا و10095 جريحا
![لبنان.. ارتفاع حصيلة ضحايا العدوان الإسرائيلي إلى 3355 قتيلا و10095 جريحا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![إسرائيل تواصل غاراتها على لبنان]() إسرائيل تواصل غاراتها على لبنان
إسرائيل تواصل غاراتها على لبنان
-
![العملية العسكرية الروسية في أوكرانيا]()
العملية العسكرية الروسية في أوكرانيا
RT STORIES
مصدر روسي: القوات الأوكرانية تتكبد خسائر فادحة في مقاطعة سومي الحدودية
![مصدر روسي: القوات الأوكرانية تتكبد خسائر فادحة في مقاطعة سومي الحدودية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
من دونه لن تصمد أوكرانيا.. جنرال هولندي يحدد شرط صمود كييف بساحة القتال
![من دونه لن تصمد أوكرانيا.. جنرال هولندي يحدد شرط صمود كييف بساحة القتال]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
وزير الحرب الأمريكي: نريد من أوكرانيا أن تدافع عن نفسها ولم نعدها بصواريخ باتريوت
![وزير الحرب الأمريكي: نريد من أوكرانيا أن تدافع عن نفسها ولم نعدها بصواريخ باتريوت]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
صحيفة: إيطاليا سترسل نحو 100 عسكري وعدة مقاتلات إلى رومانيا
![صحيفة: إيطاليا سترسل نحو 100 عسكري وعدة مقاتلات إلى رومانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
سفير موسكو في أوتاوا: كندا تنتقل من تسليح أوكرانيا إلى التصنيع المشترك معها
![سفير موسكو في أوتاوا: كندا تنتقل من تسليح أوكرانيا إلى التصنيع المشترك معها]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مؤسس شركة "بلاك ووتر" العسكرية الخاصة يعترف باهتمام عصابات المخدرات بالمقاتلين الأوكرانيين
![مؤسس شركة "بلاك ووتر" العسكرية الخاصة يعترف باهتمام عصابات المخدرات بالمقاتلين الأوكرانيين]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الدفاع الروسية: هجوم جماعي على مطارات عسكرية ومواقع بنية تحتية مرتبطة بالجيش الأوكراني
![الدفاع الروسية: هجوم جماعي على مطارات عسكرية ومواقع بنية تحتية مرتبطة بالجيش الأوكراني]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رئيس رومانيا: المسيرة ربما تحطمت في غالاتس بسبب الدفاعات الجوية الأوكرانية
![رئيس رومانيا: المسيرة ربما تحطمت في غالاتس بسبب الدفاعات الجوية الأوكرانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
حريق في ناقلة نفط وخزان وقود بميناء تاغانروغ الروسي جراء هجوم مسيرات
![حريق في ناقلة نفط وخزان وقود بميناء تاغانروغ الروسي جراء هجوم مسيرات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
قصف جوي أوكراني يسفر عن مقتل شخصين في مقاطعة بيلغورود الروسية
![قصف جوي أوكراني يسفر عن مقتل شخصين في مقاطعة بيلغورود الروسية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بوتين: روسيا لا تزال مستعدة الآن لتسوية سلمية في أوكرانيا
![بوتين: روسيا لا تزال مستعدة الآن لتسوية سلمية في أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![العملية العسكرية الروسية في أوكرانيا]() العملية العسكرية الروسية في أوكرانيا
العملية العسكرية الروسية في أوكرانيا
-
![هدنة وحصار المضيق]()
هدنة وحصار المضيق
RT STORIES
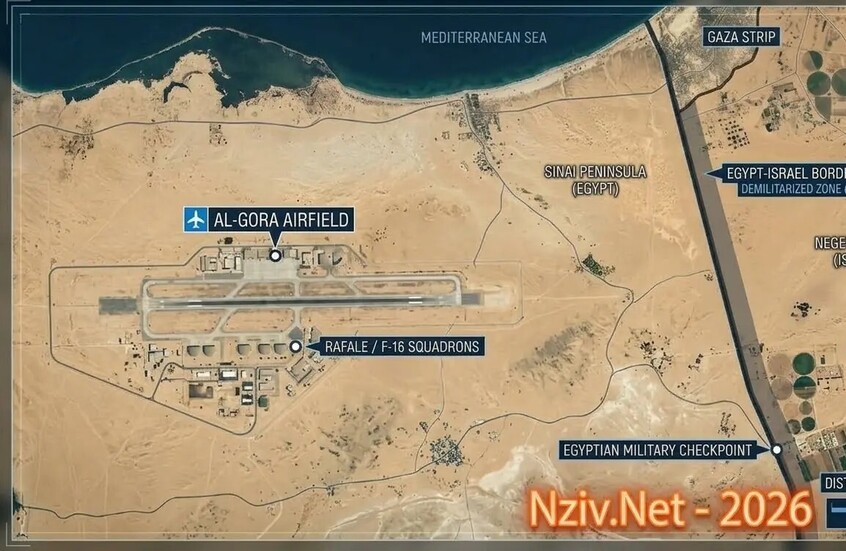
في توقيت حساس.. تحرك مصري لدعم التفاهمات الأمريكية الإيرانية
![في توقيت حساس.. تحرك مصري لدعم التفاهمات الأمريكية الإيرانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"وول ستريت جورنال": الإمارات شنت عشرات الهجمات الجوية على إيران منذ بداية الحرب
!["وول ستريت جورنال": الإمارات شنت عشرات الهجمات الجوية على إيران منذ بداية الحرب]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
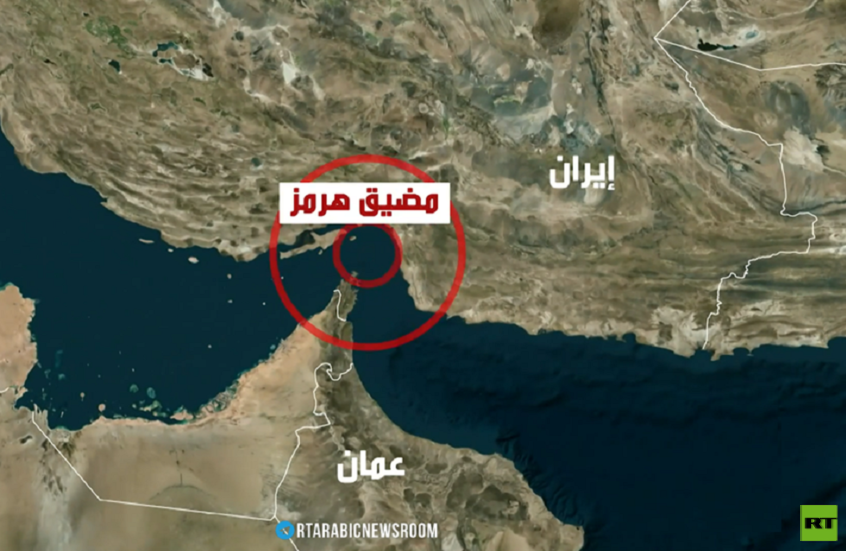
التلفزيون الإيراني: السماء والمضيق هما الخط الأحمر لإيران
![التلفزيون الإيراني: السماء والمضيق هما الخط الأحمر لإيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
فيدان: تركيا تعتبر قضية مضيق هرمز ذات أولوية أكثر من البرنامج النووي الإيراني
![فيدان: تركيا تعتبر قضية مضيق هرمز ذات أولوية أكثر من البرنامج النووي الإيراني]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
تقرير لـ"إن بي سي" يرجح إسقاط مقاتلة أمريكية فوق إيران بصاروخ صيني وبكين تنفي
![تقرير لـ"إن بي سي" يرجح إسقاط مقاتلة أمريكية فوق إيران بصاروخ صيني وبكين تنفي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"ترامب يخون الدبلوماسية للمرة الثالثة".. طهران: الحصار البحري لا يزال قائما
!["ترامب يخون الدبلوماسية للمرة الثالثة".. طهران: الحصار البحري لا يزال قائما]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بزشكيان: إيران مستعدة لإطار مشرّف لإنهاء الحرب في المنطقة
![بزشكيان: إيران مستعدة لإطار مشرّف لإنهاء الحرب في المنطقة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إصابة 5 أمريكيين وأضرار جسيمة بمسيرتين بعد سقوط حطام صاروخ إيراني على قاعدة علي السالم في الكويت
![إصابة 5 أمريكيين وأضرار جسيمة بمسيرتين بعد سقوط حطام صاروخ إيراني على قاعدة علي السالم في الكويت]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
شحنات غاز بترول مسال إيرانية تصل إلى باكستان عبر السكك الحديدية (فيديو)
![شحنات غاز بترول مسال إيرانية تصل إلى باكستان عبر السكك الحديدية (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![هدنة وحصار المضيق]() هدنة وحصار المضيق
هدنة وحصار المضيق
-
![فيديوهات]()
فيديوهات
RT STORIES
السعودية.. هدية ملكية ترافق الحجاج في رحلة العودة
![السعودية.. هدية ملكية ترافق الحجاج في رحلة العودة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
روسيا.. الثلوج تغطي إقليم خاباروفسك قبل يومين من فصل الصيف
![روسيا.. الثلوج تغطي إقليم خاباروفسك قبل يومين من فصل الصيف]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إيران.. حطام طائرة مسيرة من طراز "أوربيتر" الإسرائيلية فوق منطقة قشم
![إيران.. حطام طائرة مسيرة من طراز "أوربيتر" الإسرائيلية فوق منطقة قشم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![فيديوهات]() فيديوهات
فيديوهات
-
![زيارة بوتين إلى كازاخستان]()
زيارة بوتين إلى كازاخستان
RT STORIES
بوتين يختتم زيارة دولة إلى كازاخستان (فيديو)
![بوتين يختتم زيارة دولة إلى كازاخستان (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بوتين: لا يمكن لأحد أن يجزم بنوع المسيرة التي سقطت في رومانيا إلا بعد فحص دقيق لحطامها
![بوتين: لا يمكن لأحد أن يجزم بنوع المسيرة التي سقطت في رومانيا إلا بعد فحص دقيق لحطامها]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بوابة إفريقيا.. الاتحاد الأوراسي يطلق مفاوضات التجارة الحرة مع تونس في قمة أستانا
![بوابة إفريقيا.. الاتحاد الأوراسي يطلق مفاوضات التجارة الحرة مع تونس في قمة أستانا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
أوشاكوف: قمة الاتحاد الأوراسي ناقشت موقف أرمينيا والقادة تبنوا بيانا بشأنها
![أوشاكوف: قمة الاتحاد الأوراسي ناقشت موقف أرمينيا والقادة تبنوا بيانا بشأنها]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بوتين من أستانا: الاتحاد الاقتصادي الأوراسي يعمل بنجاح ويواصل تطوره نحو فضاء اقتصادي موحد
![بوتين من أستانا: الاتحاد الاقتصادي الأوراسي يعمل بنجاح ويواصل تطوره نحو فضاء اقتصادي موحد]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
أستانا.. الرئيس الكازاخستاني توكاييف يستقبل في قصر الاستقلال قادة دول الاتحاد الأوراسي
![أستانا.. الرئيس الكازاخستاني توكاييف يستقبل في قصر الاستقلال قادة دول الاتحاد الأوراسي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بمشاركة بوتين.. انطلاق اجتماع المجلس الاقتصادي الأوراسي الأعلى في أستانا بكازاخستان
![بمشاركة بوتين.. انطلاق اجتماع المجلس الاقتصادي الأوراسي الأعلى في أستانا بكازاخستان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![زيارة بوتين إلى كازاخستان]() زيارة بوتين إلى كازاخستان
زيارة بوتين إلى كازاخستان





























































مشكلة "الثقة المفرطة" في الذكاء الاصطناعي تقترب من الحل
قد يكون الذكاء الاصطناعي، بما يملكه من مخزون هائل من المعرفة، مفيدا للغاية، إلا أن له عيبا واحدا قد يحدّ من مزاياه، وهو الثقة المفرطة في الإجابة.

فأي إجابة يقدمها، سواء كانت مبنية على استدلال مدروس أو مجرد تخمين، يطرحها بالقدر نفسه من الثقة.
واكتشف باحثون في مختبر علوم الحاسوب والذكاء الاصطناعي بمعهد ماساتشوستس للتكنولوجيا أن أصل هذه الثقة المفرطة يعود إلى خلل محدد في طريقة تدريب النماذج، وقد طوروا أسلوبا جديدا يهدف إلى معالجة هذا الخلل دون التأثير على دقة الأداء.
وتُعرف هذه الطريقة باسم RLCR (التعلم المعزز باستخدام مكافآت المعايرة)، وقد وُصفت في بحث منشور على منصة arXiv، ومن المقرر تقديمه في المؤتمر الدولي للتعلم الآلي ICLR 2026 في ريو دي جانيرو. وتعتمد هذه المنهجية على تدريب النماذج اللغوية على تقديم إجابات مرفقة بتقدير لدرجة الثقة، أي أن النموذج لا يكتفي بالإجابة، بل يعبّر أيضا عن مستوى عدم يقينه.

ميتا تطلق أداة جديدة تتيح للآباء مراقبة محادثات أطفالهم مع الذكاء الاصطناعي
ما المشكلة؟
تقوم أساليب التعلم المعزز المستخدمة في أحدث نماذج التفكير الاصطناعي على مكافأة الإجابة الصحيحة ومعاقبة الإجابة الخاطئة، دون التمييز بين طريقة الوصول إلى النتيجة. وبالتالي، يحصل النموذج الذي يصل إلى الإجابة الصحيحة عبر استنتاج منطقي، على نفس المكافأة التي يحصل عليها نموذج آخر وصل إليها عن طريق التخمين.
ومع مرور الوقت، يؤدي ذلك إلى ترسيخ سلوك لدى النماذج يجعلها تميل إلى تقديم إجابات واثقة حتى في الحالات التي تفتقر فيها إلى الأدلة الكافية.
وتترتب على هذه الثقة المفرطة آثار سلبية، خاصة عند استخدام هذه النماذج في مجالات حساسة مثل الطب أو القانون أو التمويل، حيث تعتمد القرارات البشرية على مخرجات الذكاء الاصطناعي. فالنموذج الذي يعبر عن ثقة عالية غير دقيقة قد يكون أكثر خطورة من نموذج يخطئ بوضوح، لأن المستخدم قد لا يدرك ضرورة التحقق من الإجابة.
ويشرح طالب الدراسات العليا في معهد ماساتشوستس للتكنولوجيا وأحد مؤلفي الدراسة، ميهول داماني، قائلا:
"إن أساليب التدريب التقليدية بسيطة وفعالة، لكنها لا تشجع النموذج على التعبير عن عدم اليقين أو قول (لا أعرف)، لذلك يتعلم النموذج بطبيعته أن يخمّن عندما لا يكون واثقا".
ما الحل؟
تعالج طريقة RLCR هذه المشكلة بإضافة عنصر واحد إلى دالة المكافأة، وهو مقياس "براير" (Brier score)، المستخدم لقياس مدى تطابق ثقة النموذج مع دقته الفعلية. خلال التدريب، تتعلم النماذج تقييم كل من الإجابة وعدم يقينها في الوقت نفسه، بحيث تقدم الجواب مع تقدير لمستوى الثقة.
وبذلك تتم معاقبة كل من الإجابات الخاطئة ذات الثقة المبالغ فيها، والإجابات الصحيحة المصحوبة بعدم ثقة غير مبررة، مما يساعد على تحقيق توازن أفضل بين الدقة والتعبير الواقعي عن الثقة.
المصدر: Naukatv.ru
إقرأ المزيد

OpenAI تحل لغز الهوس الغريب لتطبيق ChatGPT بالمخلوق اﻷسطوري "غولبن"
تمكنت شركة OpenAI من حل لغز تسبب في تحول روبوت الدردشة الشهير ChatGPT إلى كائن مهووس بالمخلوقات الأسطورية، وخصوصا "الغولبن" (goblins).

لا أثق به ثقة عمياء.. مدفيديف يتحدث عن التحدي الأكبر في مواجهة الذكاء الاصطناعي
كشف نائب رئيس مجلس الأمن الروسي دميتري مدفيديف أنه يستخدم برمجيات الذكاء الاصطناعي في عمله اليومي، لكنه لا يثق بها ثقة عمياء.

DeepSeek تطلق ذكاء اصطناعيا جديدا يتفوق على معظم النماذج مفتوحة المصدر
أطلقت DeepSeek الصينية أحدث نماذجها في مجال الذكاء الاصطناعي، الإصدار الرابع (V4)، في خطوة جديدة تعكس تصاعد المنافسة العالمية في هذا القطاع.

عطل أم تصرف عدواني؟.. روبوت يفلت من السيطرة في مهرجان صيني (فيديو)
أثارت حادثة غريبة خلال مهرجان في الصين جدلا كبيرا حول سلامة الروبوتات المتقدمة، بعد أن ظهر روبوت شبيه بالإنسان وهو يتحرك بشكل غير متوقع، ما أثار صدمة الحاضرين.

DeepSeek تحذر المستخدمين من انتشار معلومات كاذبة عنها
حذّرت شركة DeepSeek الصينية مستخدمي الإنترنت من انتشار معلومات كاذبة عنها، وأوصت باستخدام مواقعها الرسمية.































































































التعليقات